只整理一些个人觉得比较重要的考点,奇怪的边缘考点直接略过
编码
这一部分的考点就是算海明码和 CRC 码。
海明码
5.2. 海明码✨
对于 m 位的码字,海明码加入了 k 位的奇偶校验码,并满足
将整体码字从 LSB 开始,按照 1 到
标注位置,奇偶校验码则放置于 的位置。
数据位位置 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 编码后数据位置 M15 M14 M13 M12 P5 M11 M10 M9 M8 M7 M6 M5 P4 M4 M3 M2 P3 M1 P2 P1 奇 偶 校 验 位 覆 盖 率 P1 X X X X X X X X X X P2 X X X X X X X X X X P3 X X X X X X X X X P4 X X X X X X X X P5 X X X X X 不同位置的奇偶校验码覆盖的范围不同,对于在
位置的奇偶校验码,从自身开始覆盖 个,然后隔 个覆盖 个(即位置 1,3,5…);对于在 位置的奇偶校验码,则是从自身开始覆盖 个,然后隔 覆盖 个(2,3,6,7…)。按照如此规律进行覆盖。 题解如下。对于例如对于一个 5 位的信息,要用偶校验和海明码实现一位错误的检测。
M5 M4 M3 M2 M1 1 1 0 1 0 要实现海明码,首先需要计算 k,使得
,这里能得到 。按照位置填入信息。并给出 1 对应的位置的二进制码
9 8 7 6 5 4 3 2 1 M5 P4 M4 M3 M2 P3 M1 P2 P1 1 1 0 1 0 1001 0111 0000 0101 0000 将所有二进制进行偶校验,
这就是对应位置的校验码。
9 8 7 6 5 4 3 2 1 M5 P4 M4 M3 M2 P3 M1 P2 P1 1 1 1 0 1 0 0 1 1 如果需要进行两位检测,再加一位对所有位的偶校验即可。
指向原始笔记的链接
CRC 码
6.3. CRC 码生成✨
是一个给定的多项式,最高项有 次。对于需要传输的信息多项式 ,先左移 位(乘 ),然后除以 得到余项 ,将余项和信息多项式相接即可得到最终的 CRC 码( )。 所以要构造 CRC 码的核心就是得到
。 Example
对于
和 ,生成最后的 CRC 码。分别用多项式和 2 进制数进行演示。 多项式形式
为 (把 0 项写出来方便解释,实际运算中省略),已知 的最高项为 ,则有 。构造新信息多项式 。
验证也很简单,就是用得到的
用来除以 如果能够除尽则说明没有错误。 指向原始笔记的链接[! info] 对于 CRC 码的完整证明需要了解多项式环(抽象数学中的一个领域)的因式分解特性。
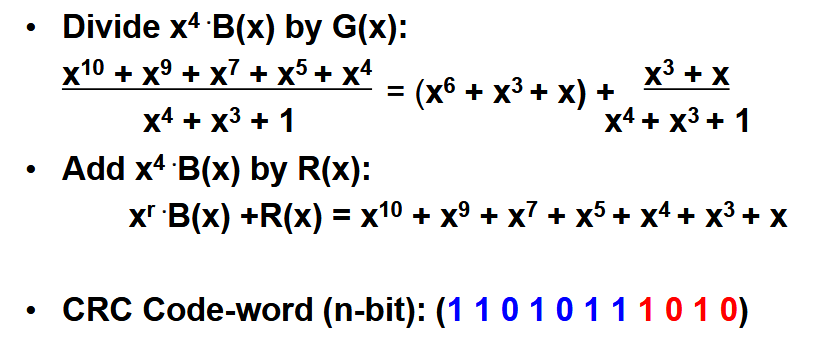
平均字长
7. 平均字长✨
这里会给出多种情况的概率,然后需要根据概率计算平均传输次数,然后乘以码长就得到的平均字长。
对于海明码和 CRC 码,具有不同的性质:
- 海明码能纠错 1 位;
- CRC 只能检错;
下面给出例题和解答过程。
假设,出错 1bit 的概率是 a,出错 2bit 的概率是 b,并且最多出现 2bit 错误。如果检测到错误,最多再传输 2 次。
对于海明码而言,传输成功的概率是 1-b,令其为
;则有失败概率为 b,令其为 。那么,平均的传输次数为, 随后再乘以码长就能得到平均字长。
对于 CRC 码而言,传输成功的概率是
,令其为 ;失败概率为 ,令其为 。同样有, 再乘字长就能得到平均字长。
指向原始笔记的链接
噪声
这里也两个考点,一个晶格图,一个串扰分析
晶格图
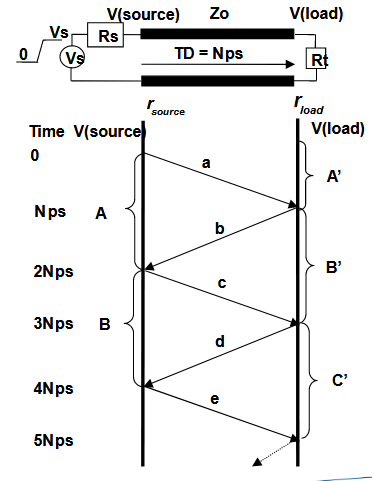
晶格图✨
晶格图是一种简化反射和波形计算的工具。图显示了边界和反射系数。时间轴垂直显示,计算每个连续反射波的电压幅度,任何点的总电压是所有已通过的波的总和。
要计算晶格图,总共有以下几个大步骤:
- 静态分析电路,即传输线两边的 TX 和 RX 的
; - 计算传输线两边的反射系数
和 ; - 计算施加在传输线上的初始电压
。 下面进行分析。
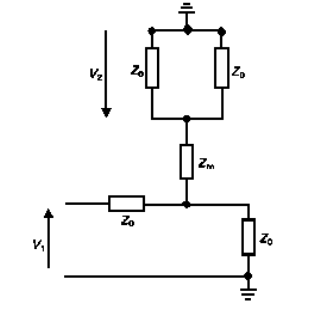
假设,电源电压从
变化到 ,电源阻抗为 ,传输线阻抗为 ,负载阻抗为 。 首先进行静态分析。此时电压波稳定,传输线不分压。有
随后进行动态分析,此时传输线分压,初始电压波只到了传输线,
随后分别计算源端和负载端的反射系数进行计算即可。
指向原始笔记的链接Note
画晶格图的时候需要注意,标注电压的时候,一定要把到达的和从这端出发的电压波都计算上。
串扰
串扰分析✨
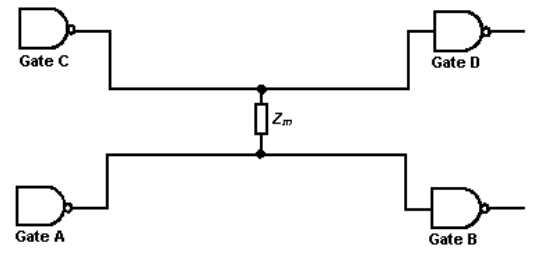
下面用单集总阻抗法来分析串扰(对分布式阻抗感兴趣的可以看 《Chapter 5 串扰耦合与分析》笔记)。
考虑两条线,中间有一个互阻抗
(这个阻抗实际上不存在,是一个集中代表了分布在两条线上的电容电感的器件)。 假设
为每条线的特征阻抗; 是门 A 的输出阻抗; 是源电压;我们将下面这条线叫作攻击线,上面的因为耦合而产生的电压波的叫受害线。 单独分析攻击线,简单的分压得到传输线上的电压
。
随后我们分析受害线。
[! hint] 分布参数模型 还记得前面给出的无损传输线的特征阻抗计算式吗?虽然很反直觉,但是特征阻抗是单位长度的特性,而非电阻的串联值。所以就算从中截断,每段的特征阻抗都是
。 互阻抗
相当于连接在两边阻抗线的“中点”,通过基尔霍夫电流定律就能得出由于 而产生的 ,
代入
后能得到, 电压
位于线路 CD 的中间点。信号在被反射并传播到门 D 之前传播到门 C。门 C 的反射信号由传输线反射系数乘以前向信号给出。假设 是门 C 的输出阻抗。门 D 处的最终电压为, [! important] 这个表达式是一个近似值。在实践中,这个问题要复杂得多。
故障
这部分的考点主要就是 SA 故障的分析。即如何获得测试向量,如何根据测试向量得到其测试的故障集。
首先整体分析总故障数量。
SA 故障数量分析
2.4. SSA 故障✨
SSA(single Stuck-At),单线固定故障,指给定线路具有恒定值 ( 0/1 ), 与电路中其他信号值无关。
2.4.1. SSA 故障的数量
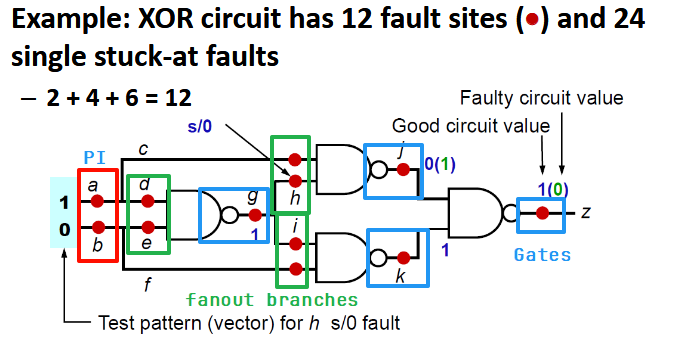
在数字电路测试中,故障点(Fault Site) 是指电路中可能发生逻辑故障的物理或逻辑位置。对于一个布尔门级电路(Boolean gate-level circuit),故障点的总数通常由以下三部分组成:
其中:
:电路的原始输入(Primary Inputs)数量。。 :电路中的逻辑门(Gates)数量。 :电路中所有扇出分支(Fanout Branches)的总数。
然后每个故障点能发生 SSA0 或者 SSA1 两种错误,所以有 24 个 SSA 错误。
指向原始笔记的链接[! tip] 除了门级电路的标准门之外,输入、输出和扇出也被定义为了组件。
测试向量推导
随后根据给出的电路和可能的故障进行故障向量的计算。
3. 测试、测试向量✨
[! note] 这一节关于“测试”的定义 故障电路产生的输出异于正常电路的输出, 其输入端的一组值叫作针对该故障电路故障的一次测试。
对电路 C 中的故障 进行测试, 就是为其提供一个输入组合,当 存在时, C 的输出与 a不存在时不同。
- 也称作测试模式或者测试向量;
检测到 ,则有 针对一类故障
的测试集是一个测试集合 , 满足 ,且 检测到 。 故障
的测试集 (布尔差分)
这里
就是原本的输出表达式; 就是发生故障后的电路输出表达式。最后得到的测试集就是需要使得 。 3.1. 测试与诊断
测试是一个包含测试模式生成、测试模式应用和输出评估的过程。
指向原始笔记的链接
- 故障检测用于判断电路是否存在故障;
- 故障定位提供检测到的故障位置;
- 故障诊断提供检测到的故障位置及类型。
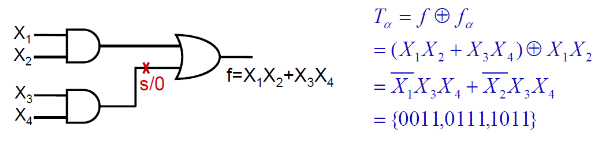
故障压缩
4. 故障压缩✨
为数字电路生成测试时, 测试工具会接收电路描述 (即网表)。随后, 工具会创建一份待检测故障的清单 (故障列表) 。对于大型电路, 列表可能会相当冗长。因此, 尽可能缩短列表是有益的。
某些故障可能会被相同的测试模式检测到。因此, 故障列表中只需包含这些故障中的一个即可。故障压缩能够通过两个概念来缩减故障列表的规模: 等效 equivalence 与支配 dominance。
4.1. 等效故障压缩
如果每一个能检测出一个故障的模式也能检测出另一个故障, 则称这两个故障是等效的。
总结:
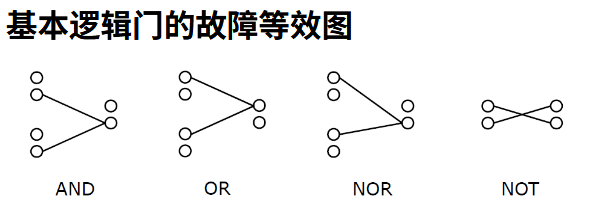
- 与门:所有 s/0 故障等效;
- 或门:所有 s/1 故障等效;
- 对于一个
输入的门电路,通过等效故障压缩,仅需要考虑 个故障。 4.1.1. 通过故障图压缩
用一对圆表示每条线 x: 上方的圆代表 x/1, 下方的圆代表 x/0。也就是说每个点代表这个接口可能出现的错误(我们这里只分析 SSA)。
拿与门进行分析。如果其某个输入 SA0,那么其输出也必然表现出 SA0,然后与这个门的输出相连的逻辑也被这个 SA0 影响,从而表现得与输入的 SA0 没有区别。
这意味着与门三个端口上的 SA0 形成一个等价类,类构件之间无法区分。我们就用一条无向的线将等价类连接起来,它们在所有可能的输入测试模式下,对电路输出的影响完全相同。
[! question] 与教材描述不同 教材这里还提到了一种浮动故障:“一个 n 输入 NOR 门在其输入上有 n 个固定 SAO 故障, 在输出上有 1 个固定 SAl 故障, 以及 1 个浮动故障 (若置于输入上则会以 SAl 的面貌出现, 若置于门的输出上则会变为 SAO)。”
但是这里没讲就先暂时不考虑。
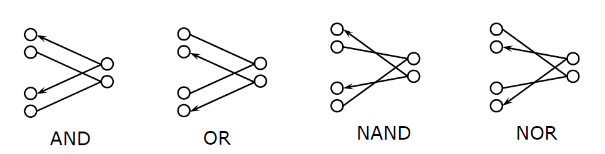
4.2. 支配故障压缩
一个故障
支配另一个故障 , 当且仅当的测试集 是前者 测试集的一个子集 ;也就是说,能检测到 的测试集 也能检测到 ,检测到 的测试集不一定意味着检测到 。 总结:
- 对于一个 n 输入与门,输出故障
支配了输入故障 ; - 对于一个 n 输入或门,输出故障
支配了输入故障 。 4.2.1. 通过故障图压缩
从支配故障向被支配故障添加有向线。支配故障等效于被支配故障,也就是说,检出了被支配故障等同于检出了支配故障,但是检出了支配故障不等于检出了被支配故障。
对于扇出结构, 将主干和分支视为独立的线路。支配方向与门电路相反。
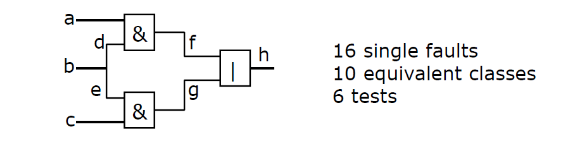
4.3. 计算故障压缩后所需测试的数量。
给出电路如上。再说明等效压缩和支配压缩在应用上的实际含意。
- 等效压缩,说明测试其中一个故障,等于所有等效的故障都测试了;
- 支配压缩,说明只要测试被支配的故障,支配故障就相当于被测试了。
所以根据前面所说的与门和或门的等效压缩和支配压缩画出图。下图是其中一种等效故障的画法。只要是等效的,你就可以连在一起;但是被支配的故障之间是无法通过一次测试覆盖,所以要分两个测试。红点就是测试点。
感谢“可爱的小天”的画图
可以看到,8 个故障点(3+3+2)可以有 16 个故障,其中有 10 个等效的类,所以只用 6 个测试就能完全覆盖。
指向原始笔记的链接

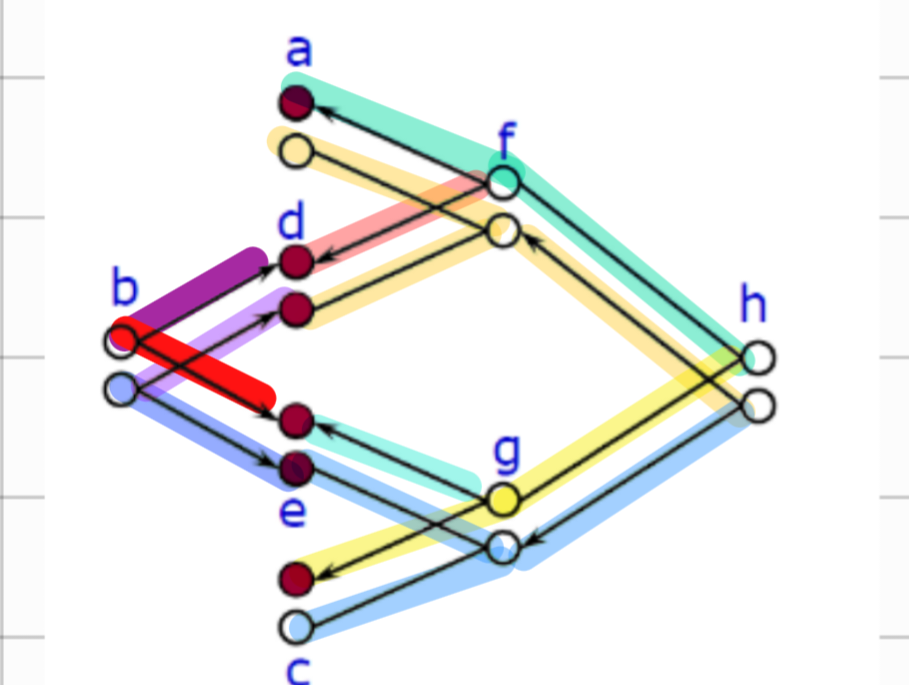
演绎故障仿真
7.4. 演绎故障仿真✨
仅仿真无故障逻辑电路的行为,每个测试模式只需一次遍历。每个故障电路中的所有信号值均从无故障电路值和电路结构推导得出。对于每个测试模式, 从输入到输出按层级顺序 (针对组合逻辑) 对所有线路应用演绎推理过程。
对于电路中的 信号线 A,其故障列表
是一个集合,包含:
- 所有 在当前逻辑状态下 能导致 A 的信号值与无故障值不同 的故障名称或索引。
- 通常针对 固定型故障(Stuck-at Faults),如 A stuck-at-0A stuck-at-0(SA0)或 A stuck-at-1A stuck-at-1(SA1)。
故障列表需要从主输入(PIs)传播至主输出(POs),为每条信号线生成一个故障列表, 并随着电路逻辑状态的每次变化而进行必要的更新。
故障列表变更时触发事件列表。
这里或门,是取
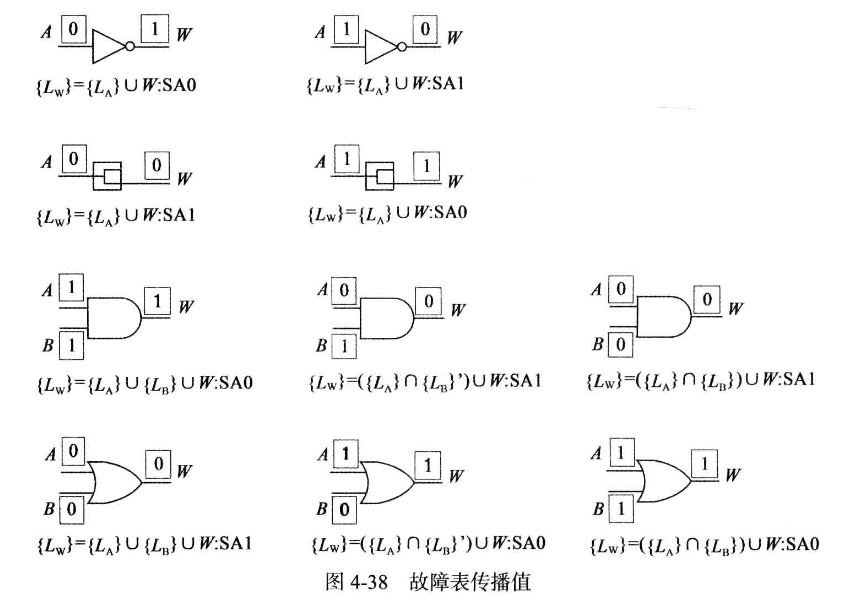
的全集的补集,再与 取交集。 下面是故障表传播值,
如果需要
指向原始笔记的链接固定, 的故障才能传播到输出的话,说明不会出现在 上的 的故障才会被传播,也就是 。
DFT
😋 不会
一、DFT 基础概念
-
什么是测试性设计(DFT)?其核心目标是什么?
- 答案:DFT 是通过设计技术提高电路的可控性和可观察性,以降低测试生成与应用成本的策略。核心目标是简化故障检测,确保测试过程高效且经济。
-
解释“可控性”与“可观察性”的含义及其对测试性的影响。
- 答案:
- 可控性:控制电路内部节点值的难易程度。高可控性便于注入测试激励。
- 可观察性:观测电路内部节点响应到输出端的难易程度。高可观察性便于捕获故障信号。
- 二者共同决定电路的测试效率,低可控性或可观察性会增加测试复杂度与成本。
- 答案:
二、Ad Hoc DFT 方法
-
列举至少三项 Ad Hoc DFT 的指导方针,并说明其作用。
- 答案:
- 电路分区:将大型电路划分为子模块,减少测试生成复杂度(例如使用多路复用器或扫描链)。
- 插入测试点:通过控制点和观察点直接干预内部信号,提升可控性和可观察性。
- 避免冗余逻辑:冗余逻辑可能掩盖故障,导致测试覆盖率下降。
- 答案:
-
Ad Hoc DFT 的主要问题是什么?如何缓解?
- 答案:
- 问题:I/O 引脚过多、测试时间长。
- 缓解方法:使用多路复用器(MUX)减少引脚数,扫描链串行化控制点以缩短测试时间。
- 答案:
三、扫描设计方法
-
扫描设计如何将时序电路测试转化为组合电路测试?
- 答案:通过将触发器替换为可扫描的 D 触发器,在测试模式下串联成移位寄存器。测试时,扫描链可加载/卸载状态,使电路在测试阶段表现为组合逻辑,简化测试生成。
-
描述扫描测试的四个基本步骤。
- 答案:
- 扫描链初始化:切换至移位模式,验证扫描链功能。
- 加载测试向量:将测试模式串行输入扫描链。
- 应用测试激励:切换至正常模式,施加主输入信号。
- 捕获并移出响应:切换回移位模式,捕获最终状态并移出结果。
- 答案:
四、部分扫描与综合症测试
-
部分扫描与全扫描的主要区别是什么?其优缺点有哪些?
- 答案:
- 区别:部分扫描仅选择部分触发器加入扫描链,全扫描则包含所有触发器。
- 优点:减少面积开销和性能影响,放宽设计规则。
- 缺点:仍需处理剩余时序逻辑,测试生成复杂度较高。
- 答案:
-
计算以下电路的综合征:( f = xz + yz’ ),并说明其是否可被综合征测试覆盖。
- 答案:
- 综合征计算:
( S (f) = \frac{\text{1 的个数}}{2^3} = \frac{4}{8} = 0.5 )。 - 测试性分析:若故障导致综合征不变(如( z/0 ) 故障,( S (f’)=0.5 )),则不可测试。需添加控制输入(如( c \cdot xz ))使其可测试。
- 综合征计算:
- 答案:
五、BIST 架构与 LFSR
-
BIST 的两大核心组件是什么?分别说明其功能。
- 答案:
- 测试生成器(TPG):生成测试向量(如 LFSR 生成伪随机序列)。
- 响应分析器(RA):压缩输出响应并比对签名(如签名分析器或 BILBO)。
- 答案:
-
LFSR 在 BIST 中的两种主要应用是什么?描述其工作原理。
- 答案:
- 伪随机模式生成:通过线性反馈生成周期性序列(周期为( 2^n-1 ))。
- 签名分析:将响应流视为多项式,通过除法取余生成唯一签名,检测错误。
- 答案:
六、签名分析与错误检测
-
解释“别名概率(Aliasing Probability)”及其计算公式。
- 答案:
- 定义:错误响应与无故障响应生成相同签名的概率。
- 公式:( P_{al} = \frac{2^{k-r} - 1}{2^k - 1} ),其中( k ) 为响应长度,( r ) 为 LFSR 位数。长序列下近似为( \frac{1}{2^r} )。
- 答案:
-
为什么 LFSR 需避免全 0 状态?如何解决?
- 答案:全 0 状态会导致 LFSR 停滞,无法生成有效序列。解决方法包括初始状态非全 0,或在反馈逻辑中强制插入 1。
| 技术 | 检测能力 | 别名概率 | 硬件复杂度 | 适用场景 |
|---|---|---|---|---|
| 签名分析 | 高(支持多比特错误) | 低(≈1/2^r) | 中等 | 复杂电路(如SoC) |
| 1计数 | 低(仅统计1的个数) | 高 | 低 | 简单组合逻辑 |
| 转换计数 | 中(对瞬态故障敏感) | 中 | 低 | 动态电路/时序测试 |
七、现代挑战与趋势
-
纳米级设计中,扫描链面临哪些新挑战?如何优化?
- 答案:
- 挑战:触发器数量激增导致测试时间过长、功耗过高、布局布线复杂。
- 优化:自适应扫描架构、多扫描链并行、基于布局的链排序。
- 答案:
-
多时钟域设计中,如何避免扫描链的时钟偏差问题?
- 答案:
- 将同一时钟域的触发器分组到同一扫描链。
- 在跨时钟域处插入锁存器(Lockup Latch)以消除时钟偏差影响。
- 答案:
存储
存储性能分析
2.3. 存储器系统性能分析 ✨
这里就涉及一个命中率 HR、缺失率 MR、平均存储器访问时间、访问效率的问题。缺失率和命中率的计算方式如下:
命中率定义式
指向原始笔记的链接 缺失率定义式
指向原始笔记的链接 平均存储器访问时间 ATAM 是处理器必须等待存储器的每条装入和存储指令的平均时间。下面用一个缓存、主存、虚拟存储的三级存储举例子。
讲解一下这个公式。就像前文所述,CPU 对存储的访问是严格按照层级来的,在访问下一个层级前必须要访问当前层级。在命中缺失的情况下,才会去访问下一级。
然后我们再来讲 PPT 上的公式。我们定义访问一个字的平均系统时间为
,访问主存 的平均时间为 ,访问辅存 的平均时间为 。设命中率为 ,则有, 同时我们有
用来描述主存的单个字访问时间, 用来描述辅存的单个字访问时间。于是有, , ,这里 是从 读取数据并传输到 的块传输时间, , 为块大小,假设为 1。代入这些内容后,就能得到, 访问效率的定义为:
[! note] 做题的时候可以先把所有数据按照题目给的条件列出来。对于同一个主存,在计算主存+缓存结构或者主存+辅存结构的时间是完全不同的,需要灵活处理。 另外,一定要区分访问存储的平均时间和单个字的访问时间。
替换算法
会推演
4.2.1.1. 替换算法 Replacement algorithms✨
- 先进先出 ( FIFO ) : 它选择内存中驻留时间最长的页面进行替换。
- LRU (时间最近最少使用) : 它选择时间上最近最少使用的页面进行替换。其依据是该页面不在当前工作集中的概率最高。
- LFU (频率最低最少使用) : 它选择替换最近一段时间被引用次数最少的页面。
- OPT (最优替换策略): 这是一种最优替换策略,将被替换的页面是那个具有最长缺页间隔(未来最长时间不会被访问的页面)的页面。这相当于在时间 T 确定下一次对同一页面的引用发生的时间
。具有最大 的页面将被替换。 OPT 算法在执行前需要预先获取页面地址流。因此, 实现 OPT 需要两次遍历程序: 第一次是模拟运行以确定页面地址序列, 第二次才是实际执行运行。由于模拟运行的成本较高, 且页面地址流可能非常长, 加之在某些情况下 (如实时系统中), 页面流可能依赖于外部事件, OPT 在实际中并不可行。 还有一种策略被称为堆栈算法,其需要满足以下性质:
表示在时间 t 时堆栈 (内存) 中的页面集合; 表示内存 (堆栈) 容量; 表示到时间 t 为止已遇到的不同页面数量。 指向原始笔记的链接Note
堆栈算法就是不断做超集,只要容量足够就包含遇到过的所有页。
内存开销与页大小的关系
要求会推导,这里算出来的
4.2.2. 内存利用率与页大小的关系✨
通常, 段大小 (
) >> 页大小 ( )。平均而言, 一个段的最后一页会浪费 个字。假设页表中的每个条目占用一个字, 那么表中将有 个字, 这是对内存的开销。 因此,与每个段相关联的内存开销
为, 我们想要
相对于 有最小值,于是我们对其求导, 令
指向原始笔记的链接,有 ,此时 有最小值。
物理空间利用率

计算逻辑空间
这里一般就给出段数、页表、页大小,然后计算逻辑空间,给出地址设计。
默认在页大小数量后面跟着的就是最小单元。
[! example]
这里 32bits 就是最小可寻址单位; 这里字节就是最小可寻址单位。
并行
性能度量
1.2. 性能度量指标 ✨
CPU 性能指标为 CPI:每条指令周期数 Cycles per instruction
指令带宽
: 吞吐量(数据带宽
):
- MFLOPS 百万次浮点运算每秒:每秒百万次浮点运算
- GFLOPS 十亿次浮点运算每秒:每秒十亿次浮点运算任务的执行时间 = 总时钟周期数 × 时钟周期时间
加速
并行度
n 级的平行度
效率
指向原始笔记的链接
并行计算机的性能分析(阿姆达尔定律)
Transclude of 《Part-6-并行处理》笔记#14-并行计算机的性能分析-
流水线性能分析
1.5. 流水线的性能分析 ✨
假设每个阶段的处理周期时间为
,假设有 个任务,每个任务花费 时间。如果使用 级流水线,总处理时间为 ;如果不使用流水线,总处理时间为 。 加速比为 。 从 Tp1 到 Tp5 的总可用处理时间为
(总可用处理时间描述的每个阶段的处理周期总和,在流水线中每个阶段的总处理周期都是 ,共 个阶段)。 总处理时间为 ,这个是需要计算所有处理器实际执行操作的时间总和,是否流水线都一样。 流水线效率为 指向原始笔记的链接[! note] 可以想象一个矩形,其长为完成
个任务所需要的时间;宽为流水线级数。
- 加速比就是使用流水线加速后,原本的完成时间与加速完成时间的比例;
- 流水线效率就是完成任务花费的时间(占用的面积)与总面积的比例。
流水线吞吐量提升
2.2. 提升吞吐量的技术 ✨
对于 M 阶段和 N 个操作, 我们有:
其中
是流水线的时钟周期。当 下降的时候,流水线吞吐量就会上升。 方法一:冗余硬件。通过使用冗余硬件来并行处理。
方法二:拆分流水线
通过增加 P 个新阶段,
减少至 , 2.2.1. 典型流水线多进程配置
在此配置中, 多个流水线处理元件被并行放置。理论上, 若有 N 个处理器, 每个处理器包含 M 级流水线, 且每个处理器完成 M 级处理需 T 秒, 则当任务中的操作数趋近于无穷大时, 系统吞吐量可接近 NM/T 次操作每秒
指向原始笔记的链接
同步
同步失败概率与 MTBF 时间
主要的计算如下,
1.3.3. 故障概率与失败频率✨
错误概率为,
失败率 failure rate为,
等待同步器失败率
指向原始笔记的链接
为输入信号频率; 为时钟频率; 为孔径时间; 为时钟周期; 为再生时间(时间常数)。 同步失败之间的平均时间(MTBF)为
。 孔径时间
Flip-Flop 的孔径时间,
即孔径时间是 Flip-Flop 的建立时间和保持时间的和。
指向原始笔记的链接等待时间
如果继续增加级数,相当于增加了
,即给亚稳态增加了衰减时间。
- 第一级:决定系统进入亚稳态的初始概率。
- 后续级:通过延长衰减时间指数级降低失败概率。 所以总的等待时间
为级联触发器总级数; 为时钟周期; 为 FF 建立时间; 为触发器时钟到输出延迟。
同步事件
1.5. 同步层次结构✨
同步的难度取决于信号事件与时钟事件之间的关系。
- 同步。信号事件总是发生在时钟禁止区域之外,例如相同时钟。
- 等时同步。信号事件以相对于时钟固定但未知的相位发生。例如同频时钟;
- 准同步。信号事件的相位随时间缓慢变化,例如略微不同的频率时钟;
- 周期性。信号事件是周期性的,包括等时和准同步,信号同步至一些周期性时钟
- 异步。信号事件随时可能发生。
同步层次摘要
指向原始笔记的链接
类型 频率 相位 同步 Synchronous 相同 相同 等时同步 Mesochronous 相同 持续 准同步 Plesiochronous 稍微不同 缓慢变化 周期同步 Periodic 不同 周期变化 异步 Asynchronous 随机 任意的