1. 并行处理
并行处理指一大类方法, 它们试图通过同时执行多个计算来提高运算速度。并行处理器是一种采用某些并行处理技术实现的计算机。
1.1. 处理器并行性(分类与类型)
按照不同的分类法有不同的分类。
1.1.1. 弗林分类法 (以迈克尔 ・J・ 弗林命名)
这些指令可被视为构成了一个指令流, 从主内存流向处理器;而操作数则形成了另一股流, 数据流, 往返于处理器之间。
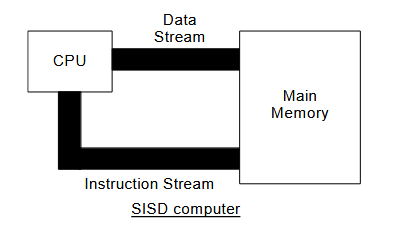
1.1.1.1. 单指令单数据 ( SISD ) 计算机
每个指令流仅与一个数据流交互。
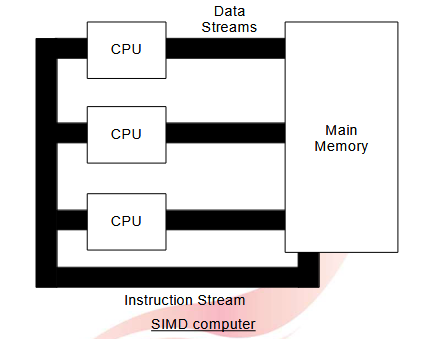
1.1.1.2. 单指令多数据 ( SIMD ) 计算机
一条指令在多个不同的数据项上并行执行。这类机器拥有不止一个 CPU。
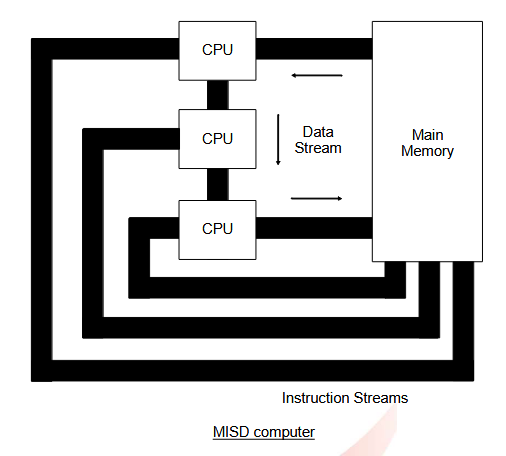
1.1.1.3. 多指令单数据 ( MISD ) 计算机
同一数据项由一组不同的指令操作。这是一种流水线架构。
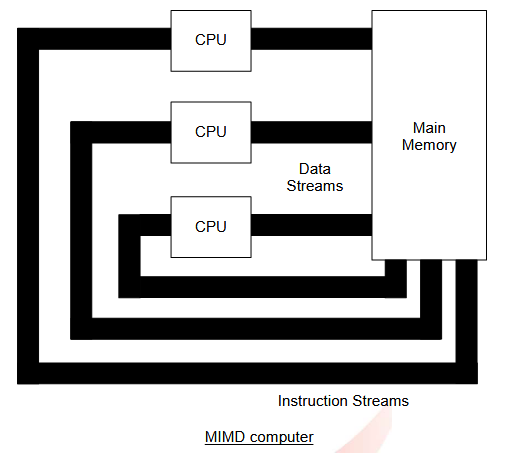
1.1.1.4. 多指令流多数据流 (MIMD) 计算机
这种就是一种多处理器架构。
1.1.2. 结构分类法
计算机系统可视为由
1.1.2.1. 共享内存结构(紧密耦合)
就是多个 CPU 共享一个主存。
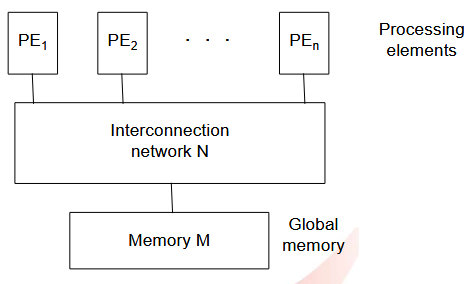
1.1.2.2. 分布式内存结构(松散耦合)
就是每个 CPU 有自己的局部内存。
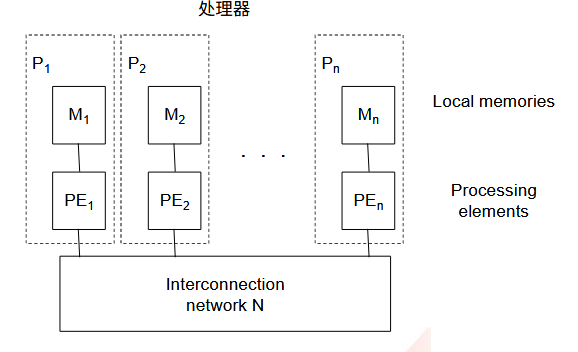
1.1.3. 拓扑结构分类法
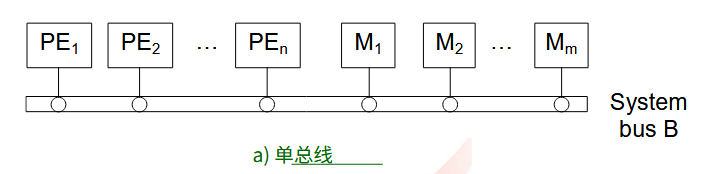
1.1.3.1. 单总线
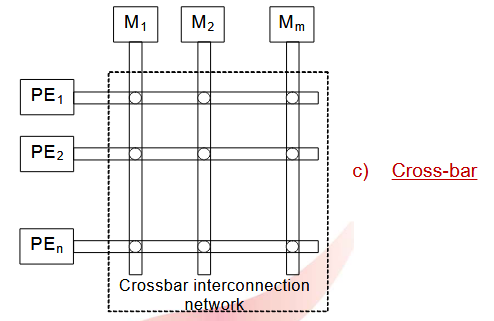
它是一种广泛使用的共享总线, 适用于并行或顺序机器。当处理单元 ( PE ) 的数量 n 和主存单元的数量 m 都很大时, 需要非常高速的总线, 并且必须采取特殊的设计预防措施以最小化对总线访问的争用。
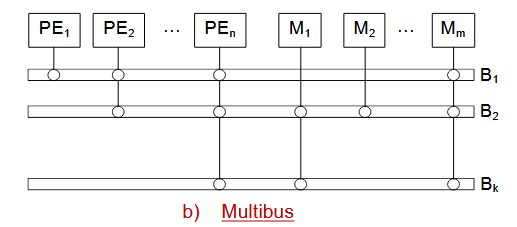
1.1.3.2. 多总线
与单一总线相比, 可以减少总线争用,每条总线的通信负载得以降低。提供了一定程度的容错能力 (性能可能有所下降), 以防总线故障。
1.1.3.3. 交叉开关
一个
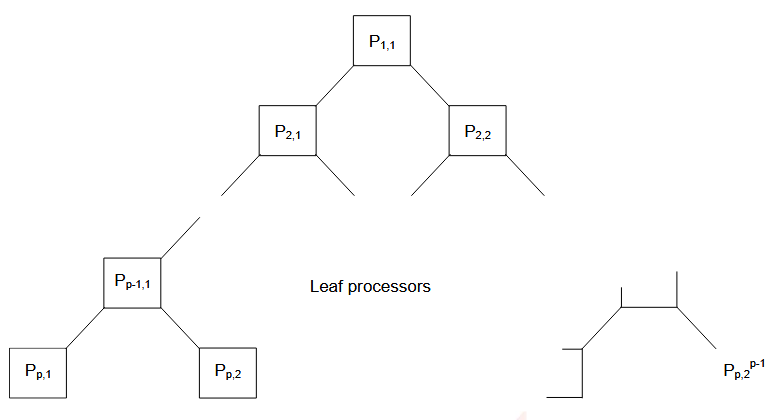
1.1.3.4. 树形结构
每个 PE (不在底行) 连接到两个 PE (其 “ 子 PE” ) ,PE 的总数为
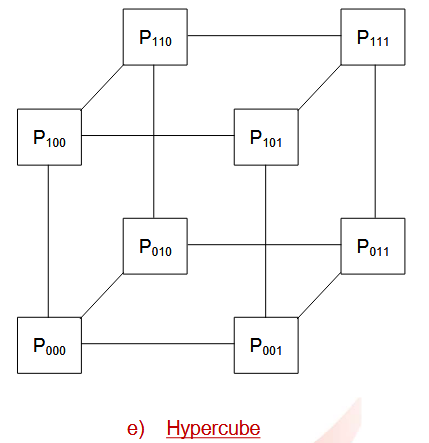
1.1.3.5. 超立方体
对于 N 维超立方体,
1.1.4. 处理器到处理器路径
- 静态树和超立方体是静态的 (固定且不可变)。专用总线。
- 动态单总线、多总线和交叉开关是动态的 (在系统控制下可重新配置)。
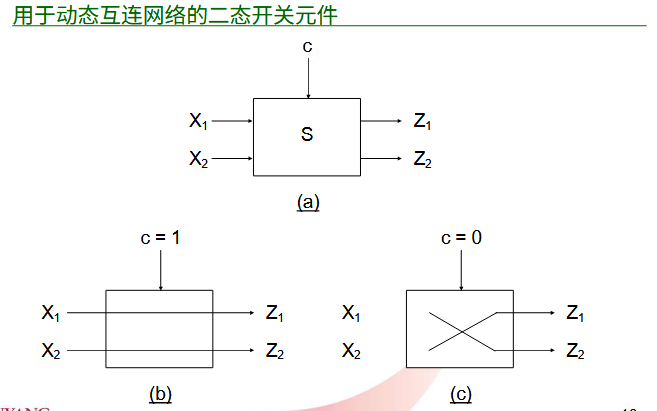
1.1.4.1. 切换元件
通常,一个动态互连网络可以通过构建使用 n 态开关来实现。
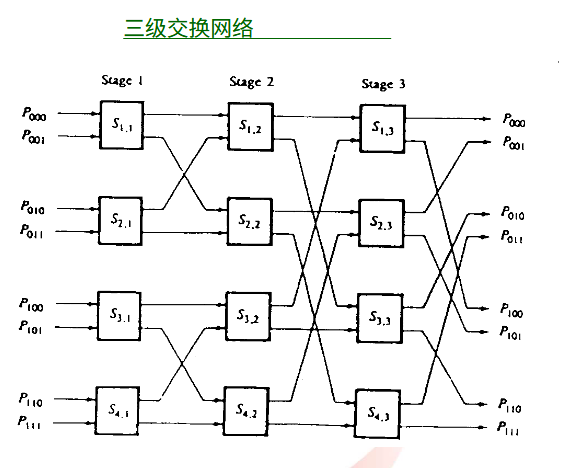
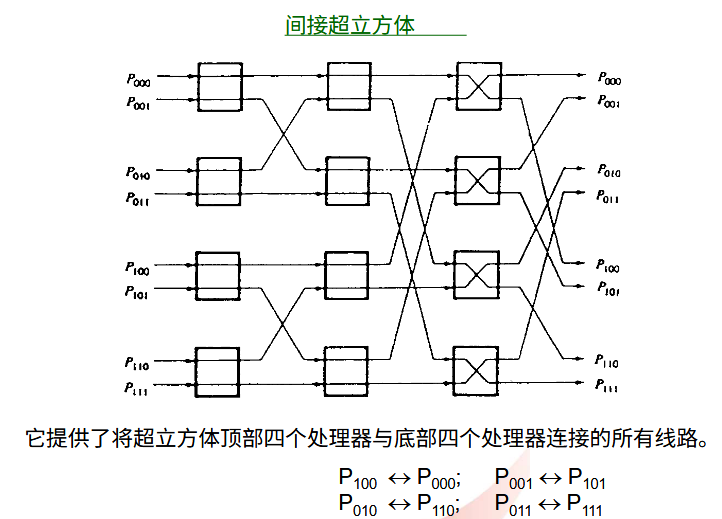
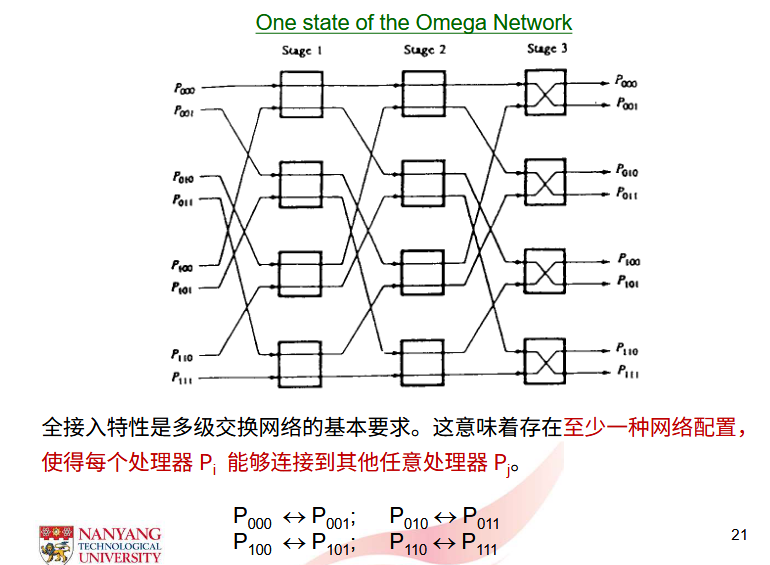
1.1.5. 共享总线中的缓存一致性
在多处理器系统中,通常, 每个处理器都有自己的缓存, 以减少系统总线的流量。缓存一致性 (缓存中的数据一致性) 问题仅通过写穿透 ( write‐through ) 流程无法解决。一个处理器可能在自身缓存及主 (全局) 内存中同时更新数据 X。若随后另一处理器更改了 X 的值, X 的新值会被写入全局内存, 但两个缓存将持有 X 的不同值。这里就出现了数据不一致的问题。
- 解决方案 1: 所有可写的共享数据均被标记为不可缓存 (即只能直接从主内存访问)。采用一种 写透过程, 要求处理器在写入共享缓存项时, 必须将该缓存项标记为无效或解除分配。
- 解决方案 2: 这是一种基于硬件的解决方案, 要求处理器将其写操作广播至所有缓存。每个缓存会检查广播项当前是否存在于自身中。若存在, 则更新或使相关缓存页 / 行失效。( IBMS/360 – 370 )(一次性写入)。
1.2. 性能度量指标 ✨
CPU 性能指标为 CPI:每条指令周期数 Cycles per instruction
指令带宽
吞吐量(数据带宽
- MFLOPS 百万次浮点运算每秒:每秒百万次浮点运算
- GFLOPS 十亿次浮点运算每秒:每秒十亿次浮点运算任务的执行时间 = 总时钟周期数 × 时钟周期时间
加速
并行度
n 级的平行度
效率
1.3. 提升吞吐量的方法
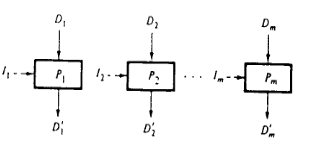
1.3.1. 一个具有多数据流 (即可以多处理) 的 m 单元处理器
1.3.2. 一个 m 段 (级) 流水线处理器
流水线处理器.png)
1.4. 并行计算机的性能分析 ✨
设 F 为所有浮点操作中以标量操作执行的比例, 那么 (1-F) 即为以向量操作执行的比例
设平均系统吞吐量为
有
然后再代入平均系统吞吐量的公式,
这里也可以看出,标量运算操作对系统平均吞吐量的影响。
加速比为
当
1.5. 流水线的性能分析 ✨
假设每个阶段的处理周期时间为
从 Tp1 到 Tp5 的总可用处理时间为
[! note] 可以想象一个矩形,其长为完成
个任务所需要的时间;宽为流水线级数。
- 加速比就是使用流水线加速后,原本的完成时间与加速完成时间的比例;
- 流水线效率就是完成任务花费的时间(占用的面积)与总面积的比例。
1.6. 缓存一致性
2. 流水线
2.1. 流水线性能
2.1.1. 加速比
如果完成一个操作需要 M 个时间单位,由顺序(非流水线)计算机完成,那么完 成 N 个操作就需要 NM 个时间单位。如果该操作被划分为 M 个阶段,每个阶段需要 一个时间单位来处理,那么仅需 N + M‐1 个时间单位就能完成这 N 个操作。因此,
加速比为
2.1.2. 管道效率
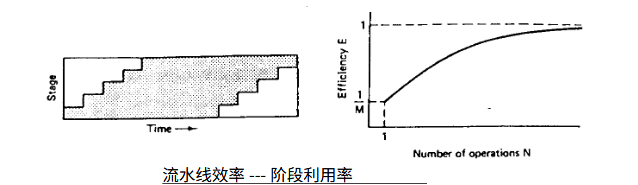
如上图所示, 阴影区域表示执行操作时处于忙碌状态的阶段, 而矩形内的非阴影区域则代表未被利用的阶段。阴影区域面积 (即所用阶段周期总数) 与矩形面积 (整个时间段内可用阶段周期总数) 之比即为效率。对于 M 个阶段和 N 个操作, 我们有
效率为
当操作阶段 M 数增加,加速比增加,但是管道效率下降。
2.2. 提升吞吐量的技术 ✨
对于 M 阶段和 N 个操作, 我们有:
其中
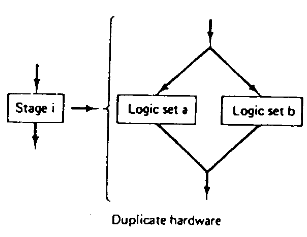
方法一:冗余硬件。通过使用冗余硬件来并行处理。
方法二:拆分流水线
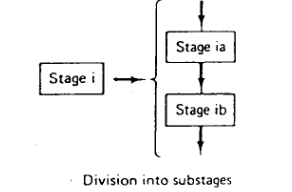
通过增加 P 个新阶段,
2.2.1. 典型流水线多进程配置
在此配置中, 多个流水线处理元件被并行放置。理论上, 若有 N 个处理器, 每个处理器包含 M 级流水线, 且每个处理器完成 M 级处理需 T 秒, 则当任务中的操作数趋近于无穷大时, 系统吞吐量可接近 NM/T 次操作每秒
3. 处理器架构
3.1. 性能指标,RISC
计算机的设计及其组织结构的研究, 包括指令集架构和硬件系统架构。
指令集架构 ( ISA ) 从机器语言程序员的角度看计算机的外观, 包括其数据类型、寄存器组、指令集以及运行时操作 (中断和 I/O 结构)。 硬件系统架构 ( HSA ) 计算机硬件系统的设计, 包括其中央处理单元、数据流组织、总线结构、控制组织以及输入输出系统。
冯 ・ 诺伊曼架构 (机器) 一种单一的存储结构, 用于同时容纳指令和数据 哈佛架构一种计算机体系结构, 具有独立的数据和指令路径通往内存。
精简指令集计算机 ( RISC ) 一台配备以下功能的计算机:
- 简单的加载 ‐ 存储指令集, 用于访问 (主) 内存。 2
- 仅支持寄存器到寄存器的操作指令。
- 大型寄存器组、多功能单元, 以及流水线化的指令与执行单元。
3.2. 超标量,超流水线
RISC 处理器的主要目标是实现单周期操作。所有早期的 RISC 处理器都能达到接近每个系统时钟周期执行一条指令的执行速度。为了进一步提升这一性能, 发展出了两类处理器, 它们能够在每个时钟周期内执行多条指令:
- 超标量处理器是 RISC 处理器的一个子类, 它允许在每个周期内并发地发出多条指令。对于超标量流水线而言, 其本质是通过复制流水线的各个阶段, 使得处于同一流水线阶段的两条或更多指令能够同时被处理, 通常伴随着低 CPI, 即。在高性能计算 ( HPC ) 和超级计算领域, 目标是实现低 CPI, 这意味着每个时钟周期能执行更多指令, 从而带来更高的效率。
- 超级流水线处理器是指那些采用多相时钟并提高时钟频率的处理器。本质上, 它们利用了更多且更细粒度的流水级。
超标量与超流水线处理器的比较
| 特性 | 超标量处理器(Superscalar Processor) | 超流水线处理器(Super-pipelined Processor) |
|---|---|---|
| 定义 | 通过使用多个执行单元,每个时钟周期执行多条指令。 | 通过增加流水线阶段数量,提升时钟频率和指令吞吐量。 |
| 并行性 | 通过同时发射多条指令实现并行性。 | 通过将指令划分为更细的流水线阶段实现更高的吞吐量。 |
| 性能 | 若存在足够多的独立指令,可显著提升性能。 | 通过减少周期时间提高吞吐量,但可能因流水线冒险而受限。 |
| 硬件复杂度 | 需要复杂的指令调度和依赖关系检查。 | 比超标量简单,但需要更好的分支预测和冒险管理。 |
| 效率 | 性能提升依赖于工作负载中的指令级并行性(ILP)。 | 性能提升依赖于减少流水线停顿和冒险。 |
| 分支惩罚 | 分支预测错误会导致多条指令被清空。 | 更长的流水线会放大分支预测错误的惩罚。 |
| 功耗 | 较高(因多执行单元和复杂控制逻辑)。 | 可能低于超标量,但因流水线停顿可能导致效率下降。 |