主要分为三个级别:
Part 1 晶体管、BiCMOS、layout
BiCMOS
BJT 能确保高开关和
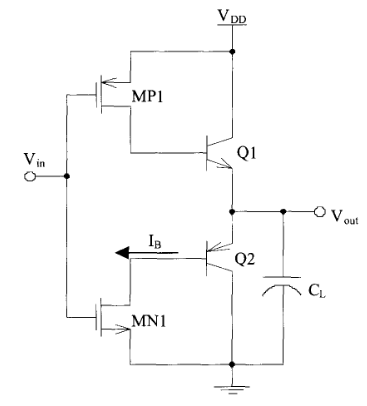
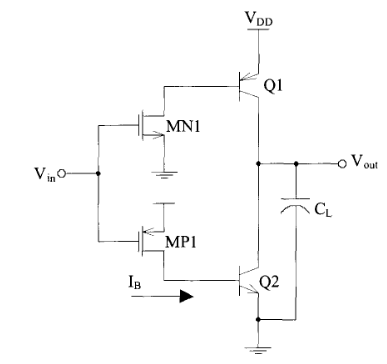
BiCMOS 逻辑电路系列中有三种通用类型的驱动器:
- 共发射极 (CE),高开关速度,但是静态功耗高;
- 门控二极管 (GD)
- 电压摆幅更低,运行速度更慢
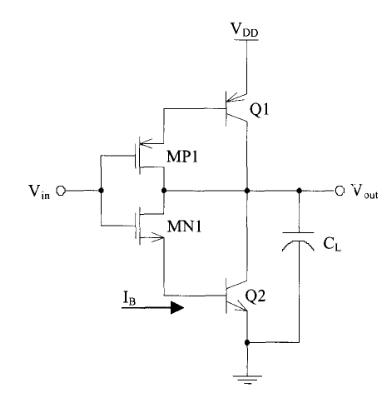
- 射极跟随器 (EF)
- 更大的电压摆幅。
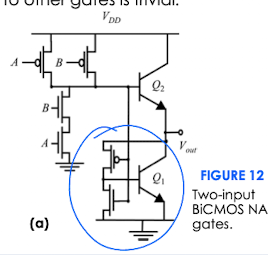
根据逻辑式画 BiCMOS
晶体管基础
长沟道 MOS 器件线性区漏极电流计算式
指向原始笔记的链接
为工艺跨导参数
NMOS 饱和区的漏极电流计算式
指向原始笔记的链接
为沟道长度调制系数。
非线性效应
- 速度饱和效应:高横向场下,电子速度不再随着电压增加而增加
- 耗尽区:不同掺杂的半导体接触的时候,因为费米能级的不平衡而导致载流子流动,只剩下固定电荷的区域
- 亚阈值:当栅极电压略小于阈值电压(
),但是没有完全使得沟道反相的时候,仍然有电流流过,这就是亚阈值漏电
延迟计算
1.6. Elmore 延时模型
有延时为,
由此就能估计节点
指向原始笔记的链接处的延迟,并且如果有从源到节点 需要经过节点 和节点 ,则有 。
电子迁移
电迁移(英语:Electromigration)是由于通电导体内的电子运动,把它们的动能传递给导体的金属离子,使离子朝电场反方向运动而逐渐迁移,导致导体的原子扩散、损失的一种现象。
热电子效应
热电子效应是指由于在器件尺寸缩小的过程中,电源电压不可能和器件尺寸按同样比例缩小,这样导致 MOS 器件内部电场增强。当 MOS 器件沟道中的电场强度超过 100kV/cm 时,电子在两次散射间获得的能量将可能超过它在散射中失去的能量,从而使一部分电子的能量显著高于热平衡时的平均动能而成为热电子
Part 2 静态、动态以及时序 CMOS
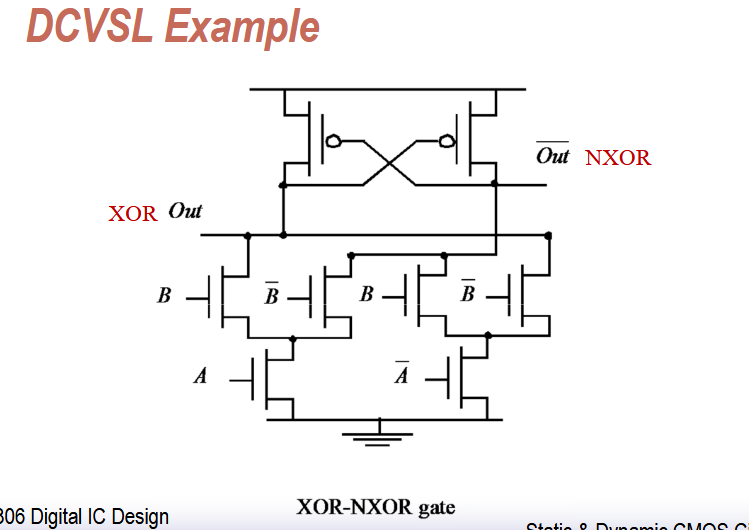
DCVSL
需要注意:
- 左边是正输出,右边是反输出
- 左边按照 complementary CMOS 的画法来,右边则是输入取反,逻辑取反的两次取反
典型的 DCVSL 门电路应该是这样,
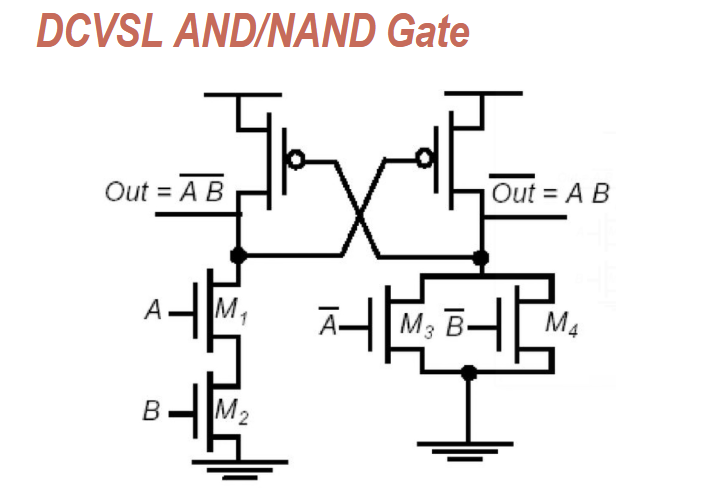
为了简化也有这种的。
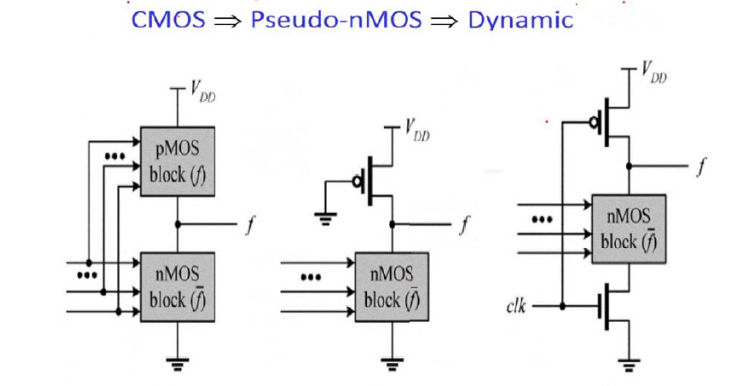
动态电路逻辑设计
动态 CMOS 在 pseudo-nMOS 的基础上发展而来,一般讨论的是预充电动态 CMOS。
静态电路
- 在存在噪声的情况下具有健壮性的优点
- 设计过程无故障,易于自动化
- 对于具有大扇入的复杂门,需要在面积和性能之间进行权衡
- 伪 nMOS 简单、快速,但代价是降低了噪声容限和静态功耗
- PTL 对于特定电路、多路复用器、加法器等 XOR 主导的逻辑很有吸引力
- DCVSL 的动态功耗低、静态功耗高,开关速度快,但是占地面积大,设计复杂
动态
- 可能实现快速且小型的复杂门
- 权衡在于寄生效应,例如电荷共享(设计过程更加复杂)困难),以及
- 电荷泄漏(需要定期刷新,这对电路的工作频率设置了下限)
静态电路逻辑设计
静态晶体管逻辑设计分为
- complementary CMOS
- ratioed logic
- pseudo nMOS
- DCVSL
- PTL
complementary CMOS 设计很简单,就是将输出取反,然后就能设计出对应的 PDN,然后再设计取反的 PUN 即可。
延迟
传播延迟主要是负载电容和晶体管电阻的函数,同时大扇入也会以二次关系增加传播延迟。
解决大扇入的方法:
- 渐进式尺寸减小。越靠近输出的尺寸越小;
- 晶体管重新排序。将最后稳定的信号放在更靠近门的位置;
- 逻辑重组。将输入分组,增加一级模组。
- 使用缓冲器。将扇入与扇出隔离。
- 减小电压摆幅。但是会导致后面的门速度减慢。
PTL 设计
PTL 设计的核心是找到控制信号,并找到输入信号和控制信号之间的关系,确实什么时候传输什么值。
一般 AND 门,
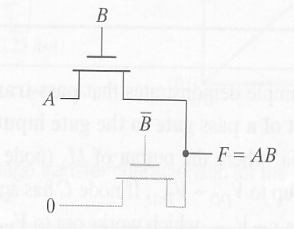
CPL 设计,就在原输出的基础上增加了互补的逻辑
晶体管 W/L 计算
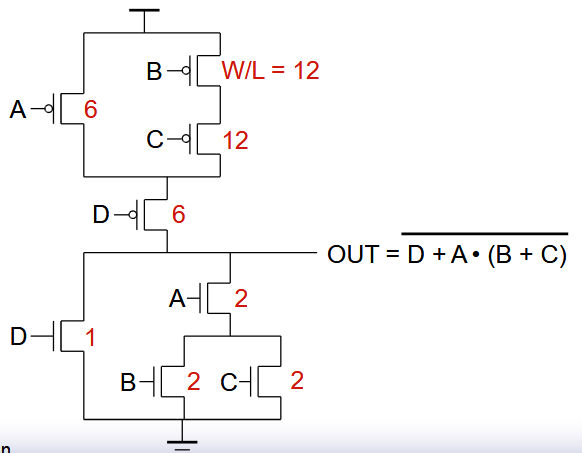 Gwee 的逻辑和 Goh 不一样。Gwee 是分治,拿 PUN 举例也就是先考虑成两个串联的模组,再细分下去。Goh 是直接算最长路径。
Gwee 的逻辑和 Goh 不一样。Gwee 是分治,拿 PUN 举例也就是先考虑成两个串联的模组,再细分下去。Goh 是直接算最长路径。
流水线
数字集成电路中的流水线技术是通过将任务分解为多个子任务,并在不同的阶段并行处理这些子任务,从而提高处理速度和效率的一种设计方法。
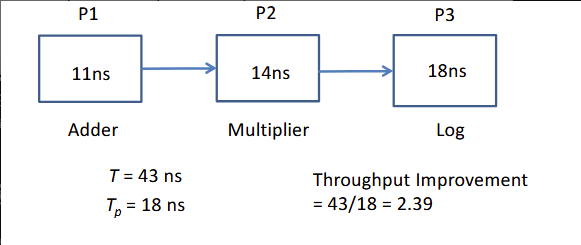 在算吞吐量提升的时候,需要理清两个概念,
在算吞吐量提升的时候,需要理清两个概念,
是未使用流水线的时候,完成总任务的周期; 是使用流水线后,(流水线跑起来后)完成总任务的周期,可以发现是所有任务模块中,占时间最长的子任务的时间; 所以用上图举例,原本的任务周期为 ,使用 3 阶(分成了 3 个子任务)流水线后的任务周期为
所以吞吐量的改善为
假设与锁存器和触发器相关的延迟可以忽略不计并,且忽略时钟偏差。提高流水线频率的方法就是再并联一个耗时最长的子模块,这样就能使得其时间减半。这样做的额外消耗就是面积会增加。
Part 3 电路子系统和设计
子系统设计
- 移位器
- 硬连线移位器
- 固定左移,固定移动位数
- 可编程移位器
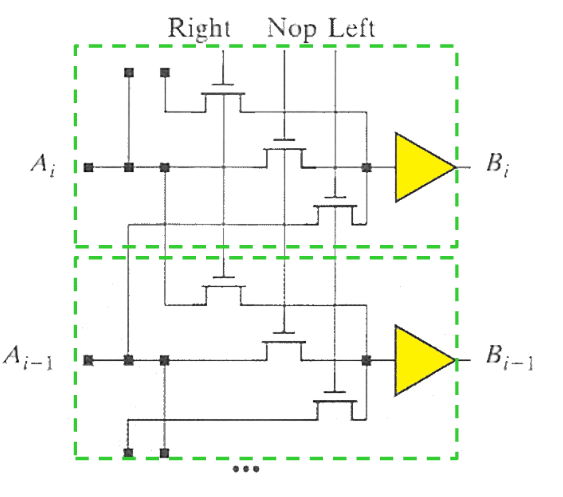
- 能左移、右移、或者不移动,三个输入只有 1 个同时为 1
- 使用 PTL 实现
- 桶式移位器
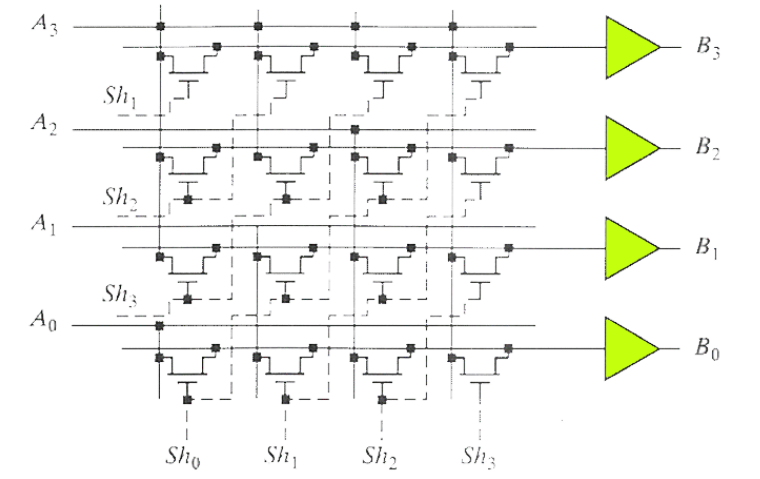
- 移动方向固定,能控制移动位数
- 行数为字长,列数为最大的移位宽度
- 左旋桶式移位器
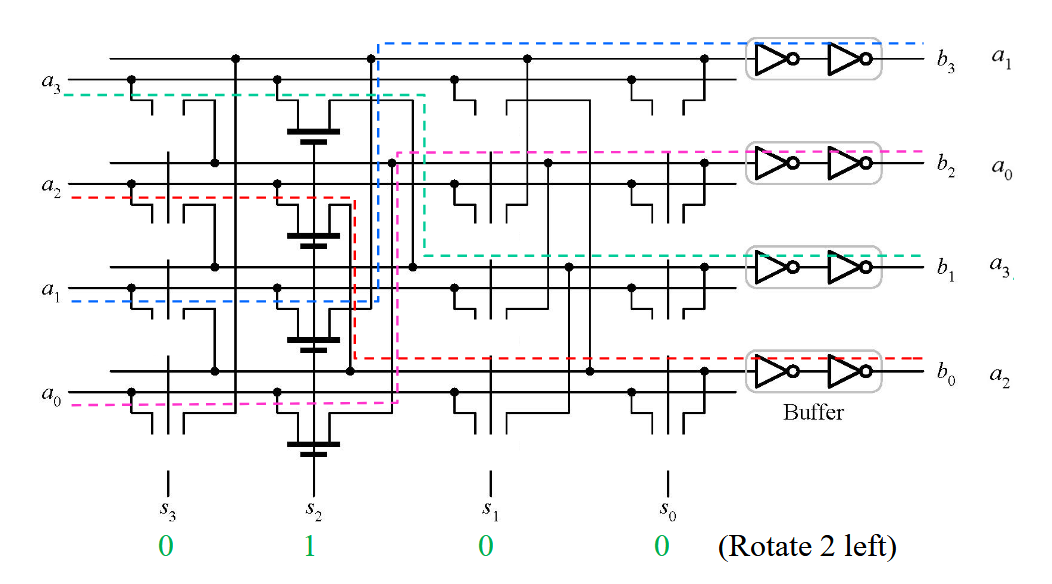
- 移动方向固定
- LSB 不会丢失,而是补充到 MSB,通路直连要去的位置
- 对数移位器
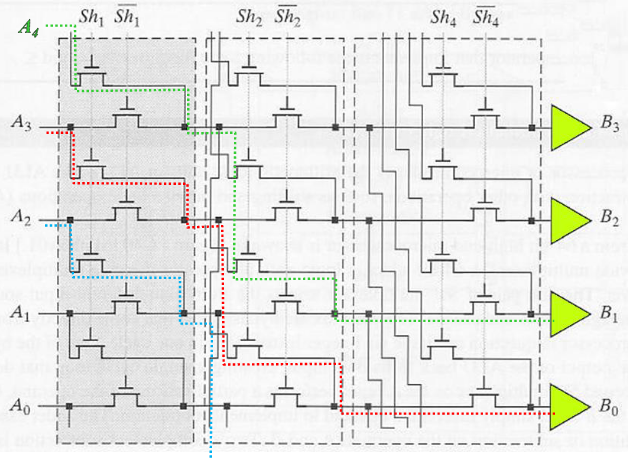
- 控制信号进行了编码,但是不需要解码器
- 速度快
- 硬连线移位器
- 加法器
- 半加器
- 不考虑进位,只考虑一位加数
- 输出一个进位与一个和
- 全加器
- 在半加器的基础上考虑来自低位的进位
- 输出一个进位与一个和
- 纹波进位加法器
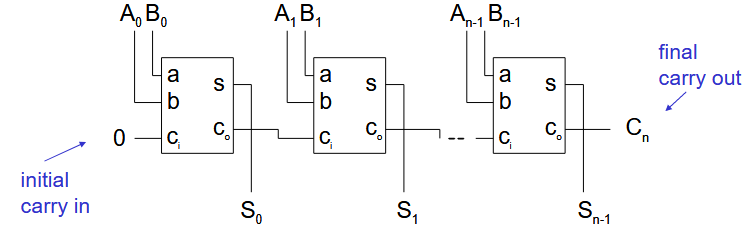
- 将全加器的进位输出连接到下一个全加器的进位输入
- 延迟为
- 加法器实现
- CMOS 实现
- 28 个 T,面积大且慢,2 个反相器传播
- 基于传输门的全加器
- 定义
, ,有
- 定义
- Manchester Carry Gates
- 定义有
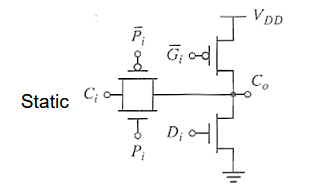
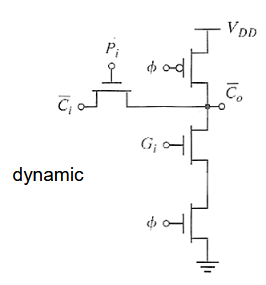
- 定义有
- CMOS 实现
- 进位旁路加法器
- 总最长延时为
- 总最长延时为
- Carry-Select Adder
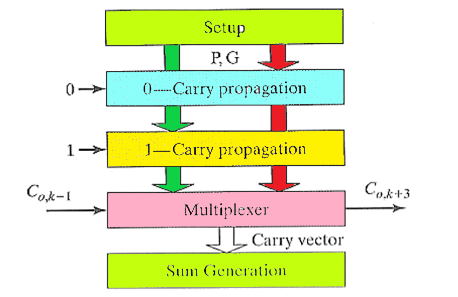
- 提前将两个结果都计算出来,然后后面的进位来的时候,根据进位进行结果的选择
- N 位平方根进位选择加法器
- 在线性进位选择加法器的基础上,通过增加每一阶的位数,使得第一阶最快,最后一阶最慢。
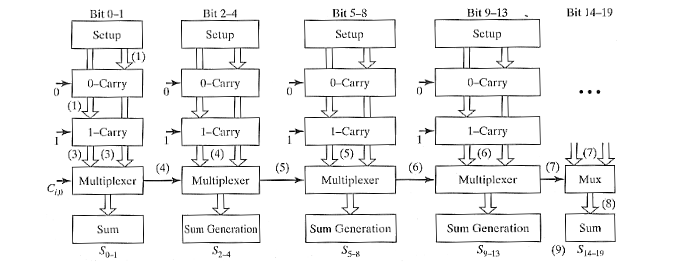
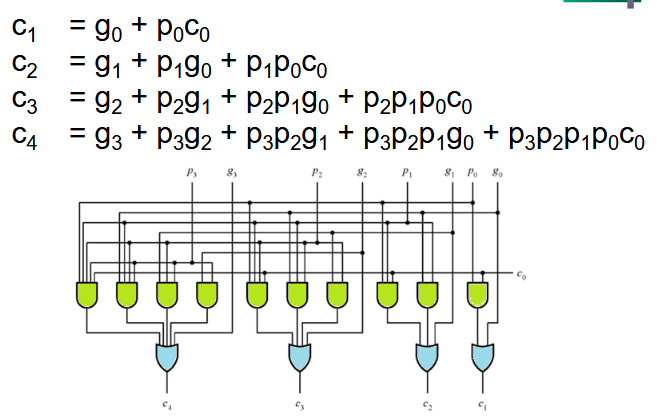
- Carry-Look-Ahead Adder
- 半加器
- 乘法器
- 位串行乘法器
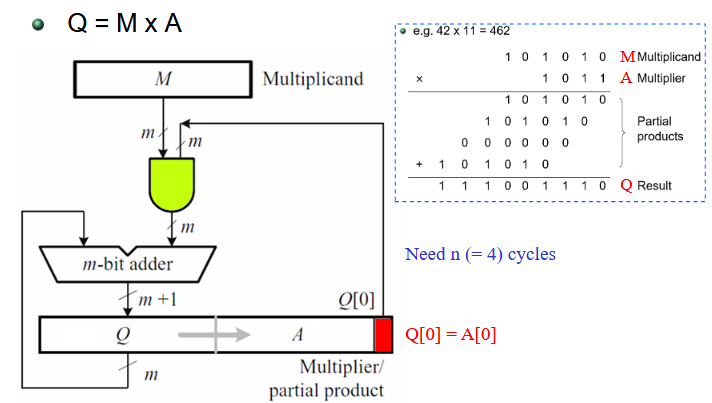
- 基础乘法器,由两个寄存器,一个与,一个 m 位加法器实现
- 首先,被乘数寄存器中会寄存被乘数 M,再将乘数 A 寄存于乘数/部分积寄存器。每次计算,都会从乘数/部分积寄存器中取出第 0 位来进行部分积运算,并将得到的部分积与来自乘数/部分积寄存器的值(初始为 0)再进行一次加和之后,存入寄存器,并将整个寄存器向右移一位,由此完成一位乘数的乘法。
- 阵列乘法器
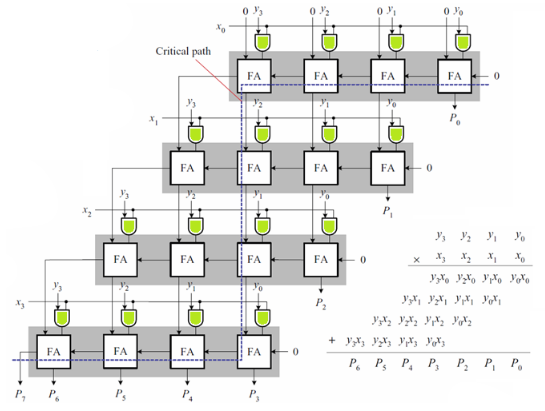
- 用阵列替代移位,实现所有被乘数(横排)与所有乘数(纵列)同时计算
- 问题在于进位,关键路径在于最长的进位路径上
- 进位保留乘法器
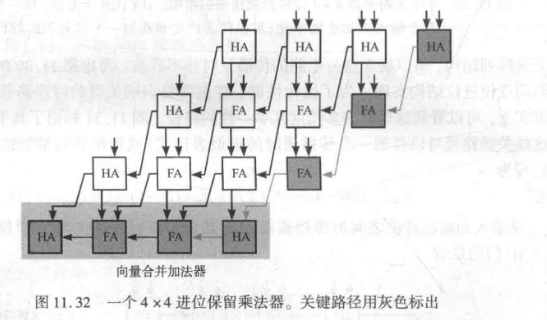
- 进位保留相较于阵列的改进之处在于,使进位输出位向下沿对角线通过
- 整体面积增加了,但是在最坏情形下关键路径最短且唯一确定
- 部分积压缩的加法器树结构
- wallace 树
- 采用尽量早压缩的策略,能通过 FA 或者 HA 压缩就压缩
- dadda 树
- 采用尽量晚压缩的策略,当点数达到阈值时,才使用加法器进行压缩
- wallace 树
- Baugh-Wooley 阵列乘法器
- 位串行乘法器
数据通路的功耗考虑,
- 多种电源电压,高速模块用高
,低速模块用低 - DVFS动态电压频率缩放,整个系统使用多个 F/V 对
- power down mode:不需要工作的模块就进入待机模式(standby mode)
设计方法
大致分为四步,
- Analysis(Simulation)
- 晶体管级仿真:使用紧凑模型
- 时序仿真:使用简单晶体管模型
- 开关级仿真:使用开关模型
- 门级仿真:使用逻辑门
- 静态时序分析:分析入口延迟、阶段延迟、输出延迟
- 功能仿真:逻辑仿真的拓展
- 行为仿真:功能和行为描述之间的差异
- Verification
- 电气验证:晶体管级原理图
- 时序验证:遍历网络并计算路径延迟
- 形式验证:在数学意义上证明电路的两种表示形式是等效的
- Implementation
- MPGA:原始单元或晶体管由供应商制造逻辑门可以通过一层或多层连接层
- PLD
- PROM:固定 AND 阵列,可编程 OR 阵列
- PLA:可编程 AND 阵列,固定 OR 阵列。
- PAL:可编程 AND 数组,可编程 OR 数组
- Synthesis
- 线路(晶体管)综合
- 逻辑门到晶体管
- 主要两个阶段
- 从逻辑方程导出晶体管网表
- 调整晶体管尺寸以满足性能约束
- 逻辑综合
- 逻辑函数到逻辑门
- 目标:优化面积、速度、功耗或其组合。
- 两个主要阶段:
- 逻辑最小化:使用多种布尔代数操作技术来优化逻辑;
- 技术映射:考虑实现架构,例如标准单元、PLA、FPGA/CPLD 等。
- 组合逻辑综合:使用定制好的组合逻辑块;
- 时序逻辑综合:
- 状态最小化:最小化状态数量。如果任何输入的输出序列相同,则两个状态是等效的;
- 状态编码:状态的不同编码可能导致不同的逻辑实现
- 状态机分解:将大型状态机分成 2 个或更小的。逻辑会更简单,更容易被最小化。速度也可以提高。
- 重定时:通过重新排列顺序逻辑元件(触发器),可以减少延迟。
- 架构综合
- 主要任务:
- 操作规划
- 在一定的约束条件下将数据流图 的操作节点分配给控制步骤
- 数据路径分配
- 将操作数(值)分配给存储元件,并将预定操作分配给物理功能模块。
- 目的是最小化存储元件数量和互连数量
- 操作规划
- 主要任务:
- 线路(晶体管)综合
- Testing
- 基于扫描的测试
- 将电路中的寄存器连接成一个长的扫描链,用于加载测试向量和输出结果。
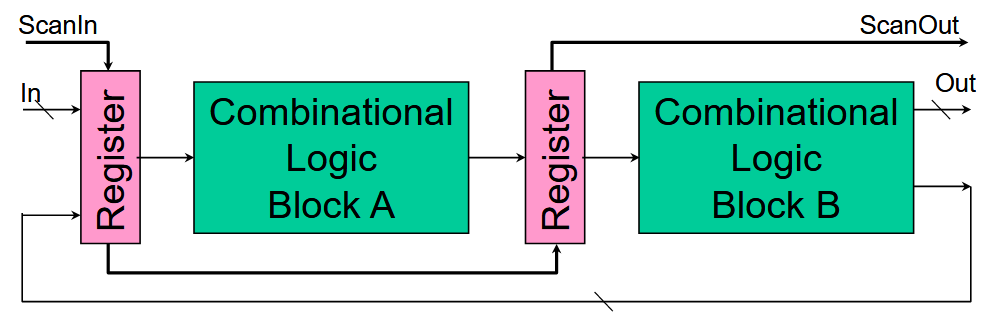
- 流程
- 构建扫描链
- 加载测试向量
- 应用测试向量
- 捕获测试向量
- 读取测试响应
- Boundary Scan Chain
- 在芯片的输入和输出引脚之间插入边界扫描寄存器,形成一个扫描链,从而允许外部测试设备对芯片的引脚状态进行控制和观察
- 工作原理
- 边界扫描寄存器
- 扫描链
- JTAG 接口
- 测试模式
- 控制和观察
- 测试向量
- 诊断和调试
- 优点在于
- 高测试覆盖率
- 非侵入性
- 可编程性
- BIST(build-in self test)
- 优点
- 自动化测试
- 高测试覆盖率
- 减少测试时间
- 降低测试成本
- 增强可靠性
- 原理
- 测试向量生成
- 测试向量应用
- 捕获
- 分析
- 优点
- 故障模型
- 信号短路
- 电源轨短路
- 浮动节点
- 基于扫描的测试